今天学到了一些识别CMS的快速方法,也算是一种信息收集经验的积累,在这里要感谢一下我的同事“gakki的童养夫”对我的大力支持。
如何判断网站的CMS?
robots.txt文件
robots.txt是网站用来防止爬虫爬取目录的文件,我们可以通过它来对CMS进行判断。
例:以下这种有很多/plus/目录的一般为织梦dedecms
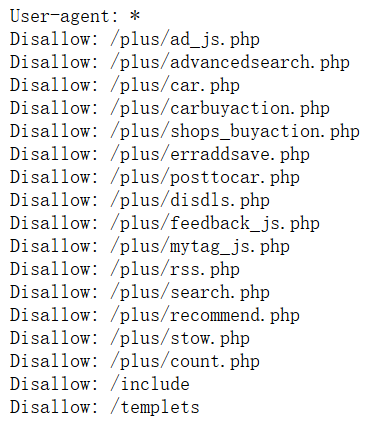
织梦的默认后台地址为xxx.com/dede/login.php,这种站一般都是一键部署的,可以尝试一下弱口令。
有的站长会修改默认路径,用域名来代替也是有可能的,例:xxx.com/xxx/login.php
未完待续。。。。